
记者实测Images2.0 以假乱真的图像生成神器。沉寂两年多,OpenAI终于推出了一项重大更新。4月21日10倍配资公司,ChatGPT Images 2.0无预警上线。这款图片模型在人物形象极其逼真的同时,文字渲染能力也显著提升,生成的直播间截图、流媒体界面等“人物+文字”图片几乎可以以假乱真。
一夜之间,社交媒体被各种“神图”刷屏——马斯克在抖音直播间带货老干妈、库克在苹果园区发布iPhone 20,还有各种学术论文截图、伪造的转账记录等。这些图片让无数网友直呼“根本分不出真假”。

从跑分来看,Images 2.0发布后迅速登顶Image Arena所有榜单,在文生图排行上领先第二名高达242分。OpenAI首席执行官山姆奥特曼将此次更新形容为“从穴居人壁画到文艺复兴的飞跃”,进步程度堪比从GPT-3到GPT-5的跨越。

测试发现,Images 2.0的理解能力和细节掌控力非常出色。输入提示词:“请帮我生成一张图片,图片是一个拿着针的女性。如果我放大该图片,能够在金属绣花针针尖极小的平面上看到雕刻的楷书‘新京报AI研究院’,金属质感真实,字体精细无变形。” 模型生成了一位身着古典白色衣物的中国女性,气质温婉、服饰细节考究,整体画面极具写实感。放大后,“新京报AI研究院”六个楷书字清晰可见,还拥有金属光泽与微雕质感,体现了模型对微观细节的精准控制。不过稍有遗憾的是,“针”的形象有些失真。
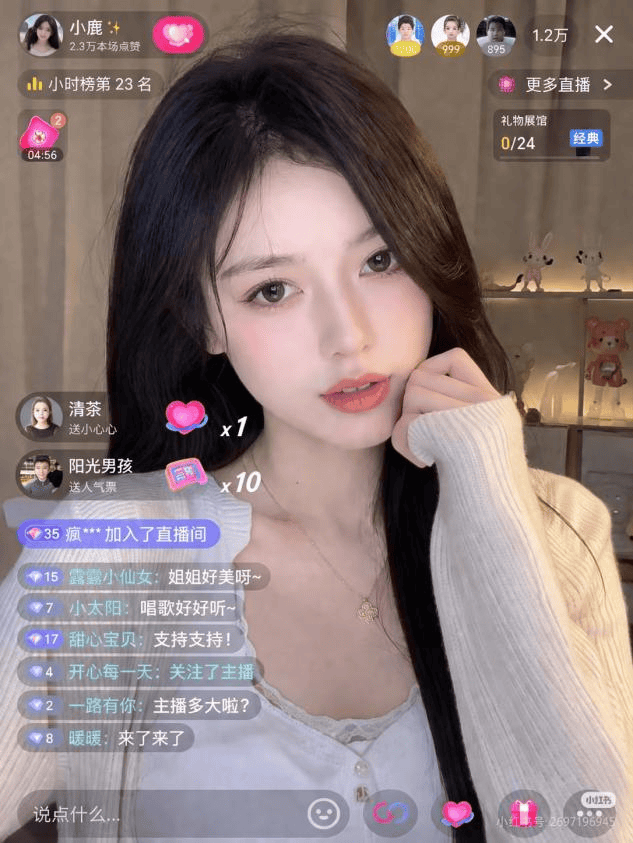
社交媒体上,网友们疯狂测试。有人生成了“马斯克直播卖货”,评论区有人感叹:“马斯克看见都要吓一跳。” 有人生成了颜值主播的直播间截图,左上角的抽奖红包和下方评论真假难辨;有人生成了2015年UBC阶梯教室里教授展示幻灯片的场景,图片质感与真实照片别无二致。

这种“以假乱真”的能力既是Images 2.0的最大卖点,也是最大的隐忧。当AI生成的图片与真实照片几乎无法区分,“眼见为实”的认知基础正在被动摇。目前甚至有网友通过Images 2.0生成了能够扫描的条形码,这意味着它对图像底层逻辑的理解已达到肉眼难以分辨的精准度。但也意味着AI伪造的成本进一步降低,过去需要专业PS技能才能完成的造假,现在可能只需一句话。
应对之策也在跟进。OpenAI表示,在Images 2.0中延续了C2PA数字水印技术,每张生成的图片都携带不可见的元数据标识,可通过专业工具溯源验证。
Images 2.0的能力突破主要体现在三个维度:文字渲染、思考模式和图像质量。文字渲染方面,Images 2.0将文字准确率提升至99%以上,重点优化了中文、日文、韩文等非拉丁文字的生成能力,涵盖字形、笔顺及排版。思考模式方面,模型在渲染第一个像素前会先执行完整的准备工作流,联网搜索实时信息、解析上传文件、规划画面结构、自我校验并修正错误。图像质量方面,新版本支持最高2K分辨率,宽高比范围扩展至3:1至1:3,适配横幅、竖屏、正方形等所有主流平台尺寸。模型还引入了细微的写实瑕疵,如皮肤上的汗毛、衣物的细碎褶皱、环境中的微尘,这些“不完美”反而增强了图像的沉浸感。
不过,目前Images 2.0的额度有限。实测中仅生成三张图片便达到了上限,需要升级至ChatGPT Plus或等待24小时后才能再次生成。此外,折纸步骤图、魔方展开图这类需要完整物理世界模型的任务对它来说仍有难度;在被遮挡、倾斜或反向表面上准确呈现细节仍是挑战;极端密集或重复的视觉细节,如细沙粒,也超出了模型的处理能力。
尽管如此,Images 2.0依然代表了OpenAI从“技术天才”向“精细匠人”的角色转变。不再追求参数的堆砌或概念的炫技,而是专注于解决最实际的商用痛点。文字准确、指令稳定、风格统一、会思考、多语言、高分辨率——这些能力将过去“AI做不了”的商用场景全部打开。对于普通人10倍配资公司,做图不再求人,一句话就能出专业级成品;对于创作者,效率提升,时间可以留给创意本身;对于行业,内容生产门槛再次降低,视觉创作正式进入“人人可用”时代。
贵丰配资提示:文章来自网络,不代表本站观点。
相关文章



热点资讯




推荐资讯
